1. 概述
全卷积网络(Fully Convolutional Networks,FCN)[1]是 Jonathan Long 等人于 2015 年提出,也是首个基于卷积神经网络的图像语义分割的方案,实现了由卷积网络实现的端到端的图像语义分割。我们回顾下,在此之前的 CNN 网络在经过多个卷积+池化层后,后将特征图拉平后,接上一个或者多个全连接层,用于分类任务或者其他,其过程如下图所示:
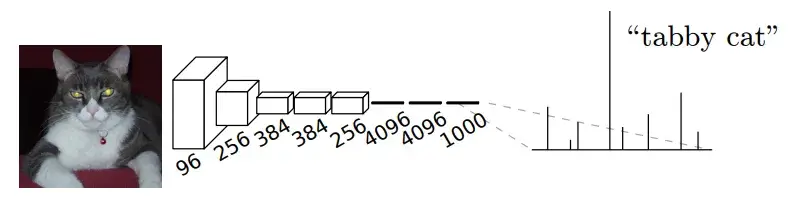
而在 FCN 中,将上面 CNN 网络后面的全连接层换成了卷积层,这样网络的输出将是热力图而非类别;同时,为解决卷积和池化导致图像尺寸的变小,使用上采样方式对图像尺寸进行恢复,如下图所示:
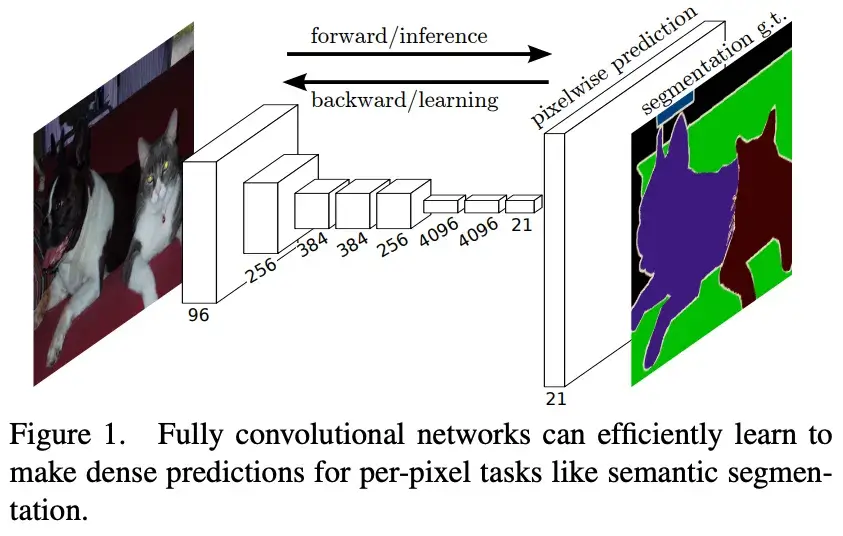
正是因为在整个网络中全部是由卷积操作构成,因此也得名为全卷积网络。
2. 算法原理
2.1. FCN 网络结构
经过上述的分析,FCN 网络结构只是在最后将全连接层换成卷积层,网络结构如下图所示:
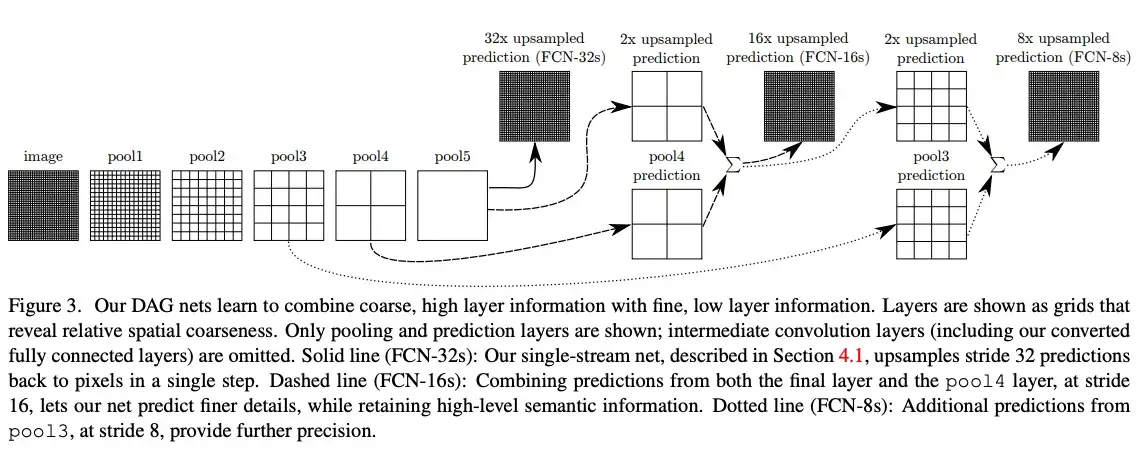
上述网络结构中分为了三种的场景,分别为:
- FCN-32s:直接对 pool5 采用 32 倍的上采样,得到 FCN-32s
- FCN-16s:将 pool5 采用 2 倍的上采样,并和 pool4 的结果相加,再进行 16 倍的上采样,得到 FCN-16s
- FCN-8s:将 pool5 采用 2 倍的上采样,并和 pool4 的结果相加的结果采用 2 倍的上采样,再与 pool3 的结果相加,再进行 8 倍的上采样,得到 FCN-8s
2.2. Backbone
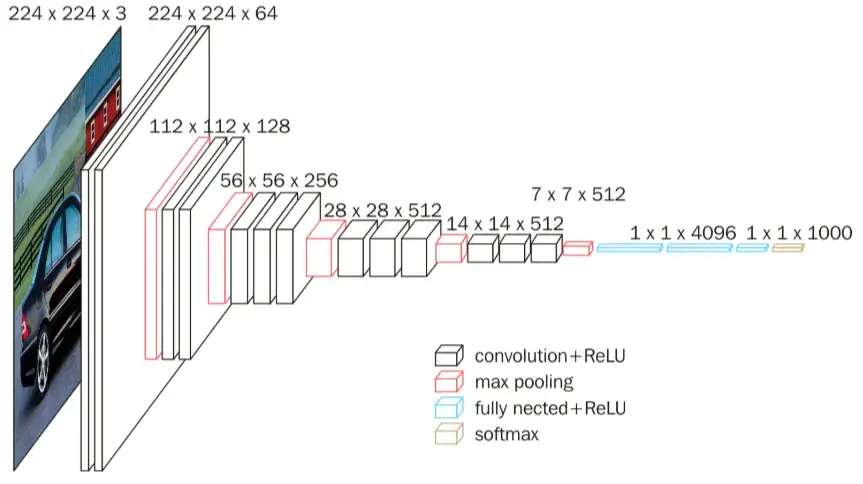
在官方的模型中,采用的是 VGG16 作为 backbone,VGG16 的网络结构如下:
2.3. 损失函数
在训练过程中,FCN 可以使用像素级别的损失函数,如交叉熵损失函数:
2.4. 上采样
上采样可以理解为是对特征图放大的操作,网上找到一张示意图(未能找到严格的出处):
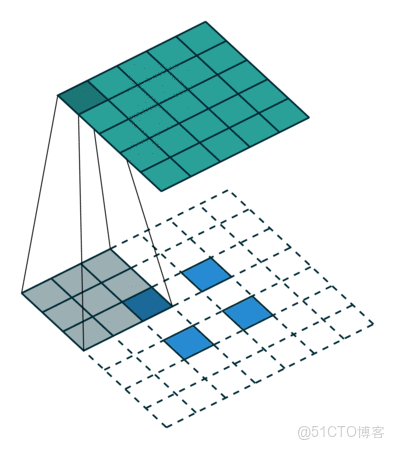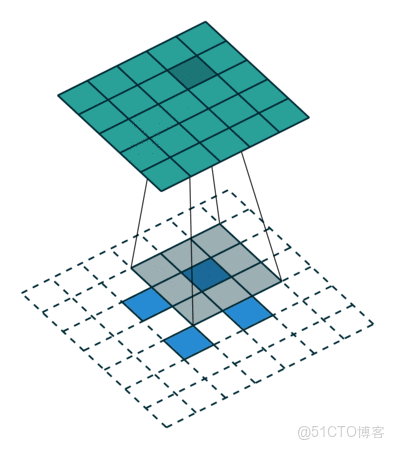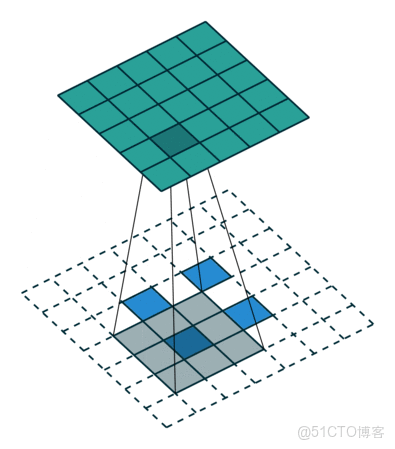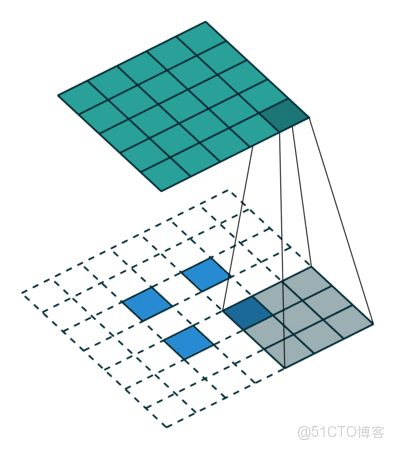
想要完成这个操作,在 PyTorch 中有两种方式,参考文献[2]中的代码也给出了这两种方式:
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
其中,nn.Upsample 是基于插值算法(如最近邻、双线性、双三次插值)直接放大特征图尺寸。最大的特点是无参数学习;nn.ConvTranspose2d 可以理解为通过转置卷积核实现上采样,本质上是卷积操作的逆过程。当然,与 nn.Upsample 相比,是包含了卷积核的权重和偏置需要学习的。
3. PyTorch 实践
3.1. 数据集
实验采用的数据集来自于 Kaggle 的 carvana-image-masking-challenge,数据集的链接见参考文献[3]。图片的示例如下图所示:
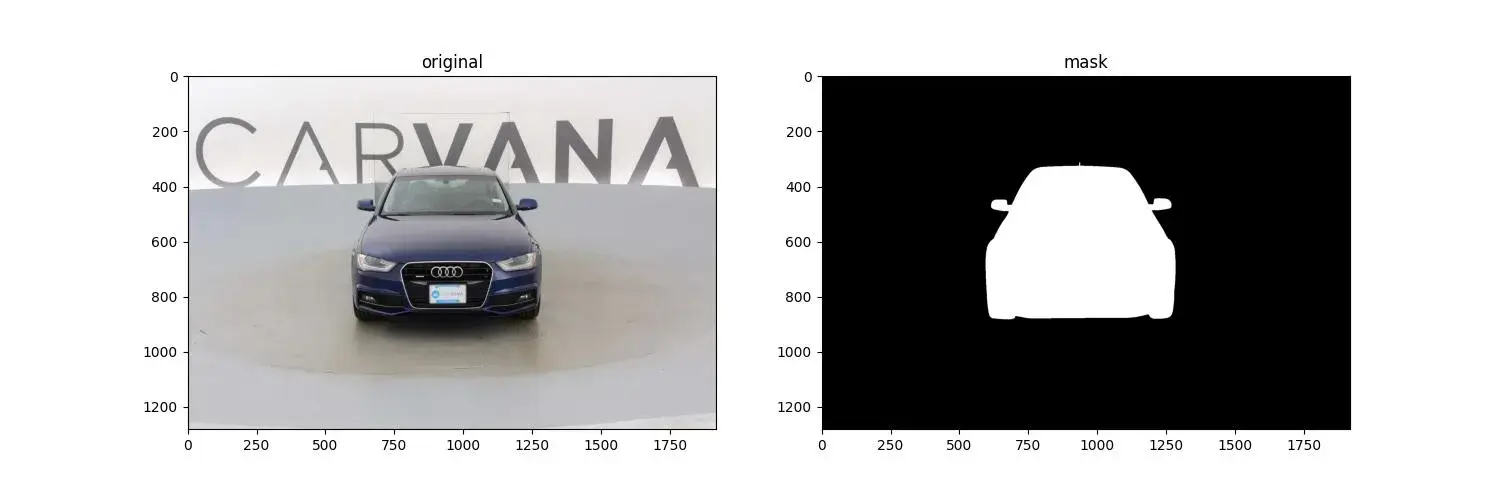
遵循 PyTorch 中数据加载的基本框架,最终形成如下的数据处理代码:
class CarvanaDataset(Dataset):
def __init__(self, root_path):
self.root_path = root_path
self.images = sorted([root_path + "/train/" + i for i in os.listdir(root_path + "/train/")])
self.masks = sorted([root_path + "/train_masks/" + i for i in os.listdir(root_path + "/train_masks/")])
self.transform_img = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406),(0.229, 0.224, 0.225))])
self.transform_mask = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()])
def __getitem__(self, index):
img = Image.open(self.images[index]).convert("RGB")
mask = Image.open(self.masks[index]).convert("L")
return self.transform_img(img), self.transform_mask(mask), self.images[index]
def __len__(self):
return len(self.images)
注:数据链接[3]中解压出来的文件夹很多,这里只取 train 文件夹和 train_masks 文件夹。
3.2. 构建模型
原文中是以 VGG16 作为 backbone,遵循原文,我们也以 VGG16 作为 backbone 构建 FCN:
class FCNModel(nn.Module):
def __init__(self, in_channels=3, num_classes=1):
super().__init__()
self.stage1 = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=64, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.stage2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.stage3 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=256),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.stage4 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.stage5 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
#k倍上采样
self.upsample_2_1 = nn.ConvTranspose2d(in_channels=512, out_channels=512, kernel_size=4, padding= 1,stride=2)
self.upsample_2_2 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=4, padding= 1,stride=2)
self.upsample_8 = nn.Sequential(
nn.ConvTranspose2d(in_channels=256, out_channels=256, kernel_size=4, padding= 1,stride=2),
nn.ConvTranspose2d(in_channels=256, out_channels=256, kernel_size=4, padding= 1,stride=2),
nn.ConvTranspose2d(in_channels=256, out_channels=256, kernel_size=4, padding= 1,stride=2)
)
#最后的预测模块
self.final = nn.Sequential(
nn.Conv2d(256, num_classes, kernel_size=1),
)
def forward(self, x):
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
pool_3 = x
x = self.stage4(x)
pool_4 = x
x = self.stage5(x)
output = self.upsample_2_1(x) + pool_4
output = self.upsample_2_2(output) + pool_3
output = self.upsample_8(output)
output = self.final(output)
return output
通过 torchinfo.summary() 函数,我们打印出 U-Net 的网络结构:
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
FCNModel [1, 1, 224, 224] --
├─Sequential: 1-1 [1, 64, 112, 112] --
│ └─Conv2d: 2-1 [1, 64, 224, 224] 1,792
│ └─BatchNorm2d: 2-2 [1, 64, 224, 224] 128
│ └─ReLU: 2-3 [1, 64, 224, 224] --
│ └─Conv2d: 2-4 [1, 64, 224, 224] 36,928
│ └─BatchNorm2d: 2-5 [1, 64, 224, 224] 128
│ └─ReLU: 2-6 [1, 64, 224, 224] --
│ └─MaxPool2d: 2-7 [1, 64, 112, 112] --
├─Sequential: 1-2 [1, 128, 56, 56] --
│ └─Conv2d: 2-8 [1, 128, 112, 112] 73,856
│ └─BatchNorm2d: 2-9 [1, 128, 112, 112] 256
│ └─ReLU: 2-10 [1, 128, 112, 112] --
│ └─Conv2d: 2-11 [1, 128, 112, 112] 147,584
│ └─BatchNorm2d: 2-12 [1, 128, 112, 112] 256
│ └─ReLU: 2-13 [1, 128, 112, 112] --
│ └─MaxPool2d: 2-14 [1, 128, 56, 56] --
├─Sequential: 1-3 [1, 256, 28, 28] --
│ └─Conv2d: 2-15 [1, 256, 56, 56] 295,168
│ └─BatchNorm2d: 2-16 [1, 256, 56, 56] 512
│ └─ReLU: 2-17 [1, 256, 56, 56] --
│ └─Conv2d: 2-18 [1, 256, 56, 56] 590,080
│ └─BatchNorm2d: 2-19 [1, 256, 56, 56] 512
│ └─ReLU: 2-20 [1, 256, 56, 56] --
│ └─Conv2d: 2-21 [1, 256, 56, 56] 590,080
│ └─BatchNorm2d: 2-22 [1, 256, 56, 56] 512
│ └─ReLU: 2-23 [1, 256, 56, 56] --
│ └─MaxPool2d: 2-24 [1, 256, 28, 28] --
├─Sequential: 1-4 [1, 512, 14, 14] --
│ └─Conv2d: 2-25 [1, 512, 28, 28] 1,180,160
│ └─BatchNorm2d: 2-26 [1, 512, 28, 28] 1,024
│ └─ReLU: 2-27 [1, 512, 28, 28] --
│ └─Conv2d: 2-28 [1, 512, 28, 28] 2,359,808
│ └─BatchNorm2d: 2-29 [1, 512, 28, 28] 1,024
│ └─ReLU: 2-30 [1, 512, 28, 28] --
│ └─Conv2d: 2-31 [1, 512, 28, 28] 2,359,808
│ └─BatchNorm2d: 2-32 [1, 512, 28, 28] 1,024
│ └─ReLU: 2-33 [1, 512, 28, 28] --
│ └─MaxPool2d: 2-34 [1, 512, 14, 14] --
├─Sequential: 1-5 [1, 512, 7, 7] --
│ └─Conv2d: 2-35 [1, 512, 14, 14] 2,359,808
│ └─BatchNorm2d: 2-36 [1, 512, 14, 14] 1,024
│ └─ReLU: 2-37 [1, 512, 14, 14] --
│ └─Conv2d: 2-38 [1, 512, 14, 14] 2,359,808
│ └─BatchNorm2d: 2-39 [1, 512, 14, 14] 1,024
│ └─ReLU: 2-40 [1, 512, 14, 14] --
│ └─Conv2d: 2-41 [1, 512, 14, 14] 2,359,808
│ └─BatchNorm2d: 2-42 [1, 512, 14, 14] 1,024
│ └─ReLU: 2-43 [1, 512, 14, 14] --
│ └─MaxPool2d: 2-44 [1, 512, 7, 7] --
├─ConvTranspose2d: 1-6 [1, 512, 14, 14] 4,194,816
├─ConvTranspose2d: 1-7 [1, 256, 28, 28] 2,097,408
├─Sequential: 1-8 [1, 256, 224, 224] --
│ └─ConvTranspose2d: 2-45 [1, 256, 56, 56] 1,048,832
│ └─ConvTranspose2d: 2-46 [1, 256, 112, 112] 1,048,832
│ └─ConvTranspose2d: 2-47 [1, 256, 224, 224] 1,048,832
├─Sequential: 1-9 [1, 1, 224, 224] --
│ └─Conv2d: 2-48 [1, 1, 224, 224] 257
==========================================================================================
Total params: 24,162,113
Trainable params: 24,162,113
Non-trainable params: 0
Total mult-adds (G): 86.91
==========================================================================================
Input size (MB): 0.60
Forward/backward pass size (MB): 354.44
Params size (MB): 96.65
Estimated Total Size (MB): 451.69
==========================================================================================
上述代码中在实现 8 倍的上采样时,并没有直接使用大的卷积核,而是通过多个小的卷积核的堆叠实现了 8 倍的上采样。
3.3. 模型训练
详细代码如下:
class FCN:
def __init__(self, WORKING_DIR=None):
self.WORKING_DIR = WORKING_DIR
def train(self):
# 1. 加载数据,拆分训练集和验证集
train_dataset = CarvanaDataset(self.WORKING_DIR)
generator = torch.Generator().manual_seed(25)
train_dataset, val_dataset = random_split(train_dataset, [0.8, 0.2], generator=generator)
device = "cuda" if torch.cuda.is_available() else "cpu"
if device == "cuda":
num_workers = torch.cuda.device_count() * 4
LEARNING_RATE = 3e-4
BATCH_SIZE = 64
train_dataloader = DataLoader(dataset=train_dataset,
num_workers=num_workers,
pin_memory=False,
batch_size=BATCH_SIZE,
shuffle=True)
val_dataloader = DataLoader(dataset=val_dataset,
num_workers=num_workers,
pin_memory=False,
batch_size=BATCH_SIZE,
shuffle=True)
model = FCNModel(in_channels=3, num_classes=1).to(device)
# INFO: 设计模型参数
optimizer = optim.AdamW(model.parameters(), lr=LEARNING_RATE)
criterion = nn.BCEWithLogitsLoss()
EPOCHS = 200
train_losses = []
val_losses = []
best_val = float('inf')
for epoch in tqdm(range(EPOCHS), desc="EPOCHS", leave=True):
model.train()
train_running_loss = 0
for idx, img_mask in enumerate(tqdm(train_dataloader, desc="Training", leave=True)):
img = img_mask[0].float().to(device)
mask = img_mask[1].float().to(device)
y_pred = model(img)
optimizer.zero_grad()
loss = criterion(y_pred, mask)
train_running_loss += loss.item()
loss.backward()
optimizer.step()
train_loss = train_running_loss
train_losses.append(train_loss)
# 在验证集上验证
model.eval()
val_running_loss = 0
with torch.no_grad():
for idx, img_mask in enumerate(tqdm(val_dataloader, desc="Validation", leave=True)):
img = img_mask[0].float().to(device)
mask = img_mask[1].float().to(device)
y_pred = model(img)
loss = criterion(y_pred, mask)
val_running_loss += loss.item()
val_loss = val_running_loss
if val_loss < best_val:
best_val = val_loss
torch.save(model.state_dict(), 'best_fcn.pth')
val_losses.append(val_loss)
# INFO: 记录
EPOCHS_plot = []
train_losses_plot = []
val_losses_plot = []
for i in range(0, EPOCHS, 5):
EPOCHS_plot.append(i)
train_losses_plot.append(train_losses[i])
val_losses_plot.append(val_losses[i])
print(f"EPOCHS_plot: {EPOCHS_plot}")
print(f"train_losses_plot: {train_losses_plot}")
print(f"val_losses_plot: {val_losses_plot}")
plot_losses(EPOCHS_plot, train_losses_plot, val_losses_plot, "fcn_train_val_losses.jpg")
在训练的过程中,我们也记录了损失函数的变化:
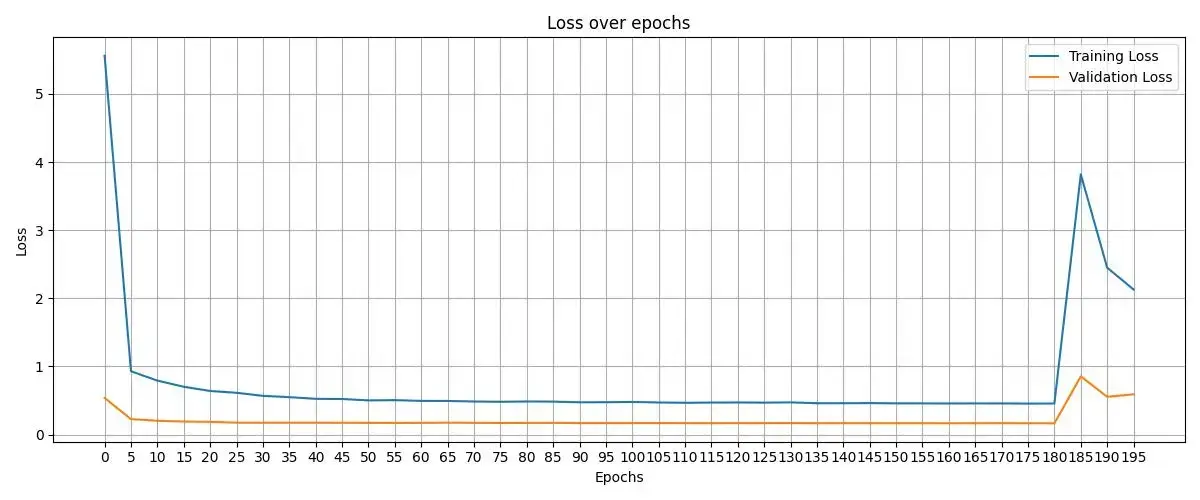
在模型的训练后期出现了波动,这很大程度上与设计的优化器的学习率 LEARNING_RATE 有关,在此可以尝试使用一些动态的学习率来避免后期因学习率过大导致的效果的波动。
3.4. 模型预测
训练完成后,我们保存了在验证集上效果最好的模型 best_fcn.pth,接下来需要通过模型直接对新的图片预测,直接上代码,以下是预测部分的代码:
def predict(self, img, model_path):
w, h = img.size
ori_size = (h, w)
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406),(0.229, 0.224, 0.225))])
device = "cuda" if torch.cuda.is_available() else "cpu"
model = FCNModel(in_channels=3, num_classes=1).to(device)
model.load_state_dict(torch.load(model_path,
map_location=torch.device(device),
weights_only=True))
# 开始推理
model.eval()
with torch.inference_mode():
tensor_image = transform(img)
tensor_image = tensor_image.float().to(device)
# 增加 batch 维度
pred_mask = model(tensor_image.unsqueeze(0))
# 取消 batch 维度
pred_mask = pred_mask.squeeze(0)
img_resize = transforms.Resize(ori_size)
pred_mask = img_resize(pred_mask).permute(1,2,0)
pred_mask = pred_mask.cpu().detach()
pred_mask[pred_mask < 0] = 0
pred_mask[pred_mask > 0] = 1
numpy_image = pred_mask.numpy()
numpy_image = (numpy_image * 255).astype(np.uint8)
numpy_image = numpy_image.squeeze(-1)
return Image.fromarray(numpy_image)
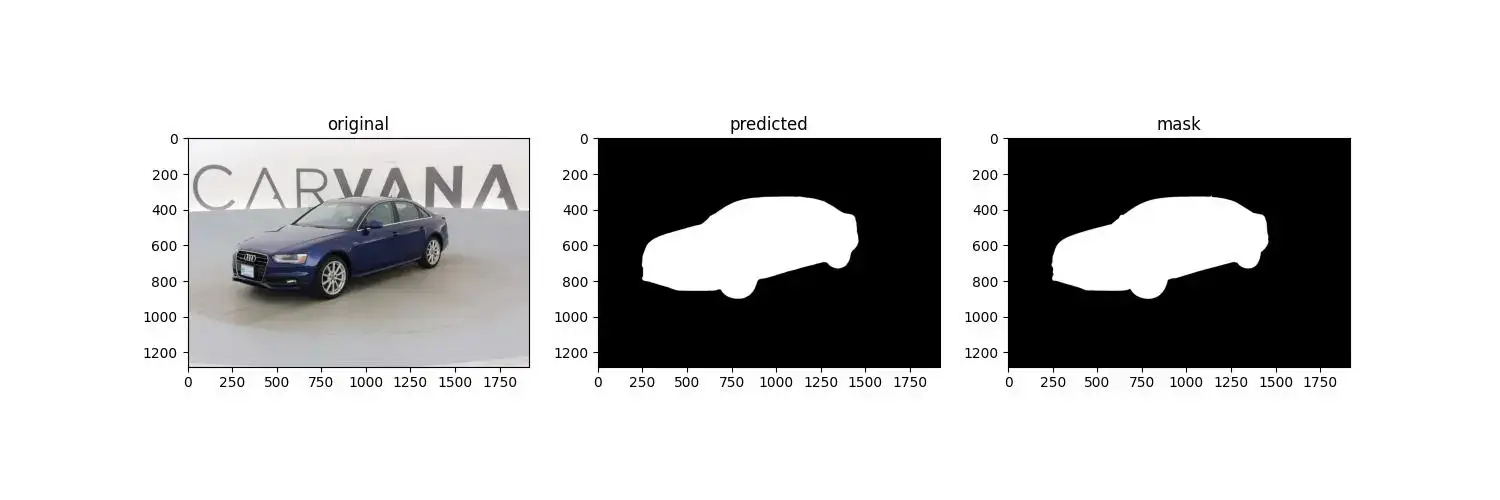
可以对部分结构做个可视化,如下图:
4. 总结
本文中只是对全卷积神经网络 FCN 原理的介绍,以及基于原理的基本实现,在训练的过程中还有很多需要优化的地方,如使用更好的 backbone,如 resnet 等。对于具体的问题,还有很多需要优化和修改的地方。
参考文献
[1] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3431-3440.
[2] https://github.com/milesial/Pytorch-UNet/blob/master/unet/unet_parts.py
[3] https://www.kaggle.com/c/carvana-image-masking-challenge/data