1. 概述
U-Net[1] 最初是于 2015 年为参加 ISBI Challenge 提出的一种分割网络,用于解决图像语义分割的任务。在开始介绍 U-Net 网络结构之前,先对图像分割任务做简单的介绍,简单来说,图像分割就是按照某个性质(如语义)将图像分割成多个部分。图像分割任务分为以下的几种:
- 语义分割( Semantic Segmentation ):即对图像中的每个像素点分类,相同类别的划分到同一个类别。
- 实例分割(Instance Segmentation ):即在图像中找到特定的目标,并对检测到的目标进行分割。与语义分割不同的是,实例分割在语义分割的基础上还要区分不同的实例。
- 全景分割(Panoptic Segmentation):可以理解为语义分割和实例分割的结合,会对图中所有物体包括背景都要进行检测和分割。
为了更好的理解上述的概念,在参考文献[2]中找到了对上述概念的解释的图:

其中,图 a 是一张原图,图 b 是语义分割,在分割结果中,将相同类别的区域标记成同样的颜色;图 c 是实例分割,对于同样是汽车,按照实例分割成不同的实例;最后图 d 是全景分割,是上述语义分割和实例分割的结合体。本文所介绍的 U-Net 属于语义分割的一种。
2. 算法原理
2.1. U-Net 的网络结构
语义分割需要对图像中的每一个像素点分类,从语义分割的定义来看,最直接的方式就是将每一个像素点标记为类别,也正是基于这种思想,U-Net 网络中,通过深度网络将每一个像素点映射到不同的类别,注意,此时设计的输入和输出的图像的大小是一致的。具体的网络结构如下图所示:
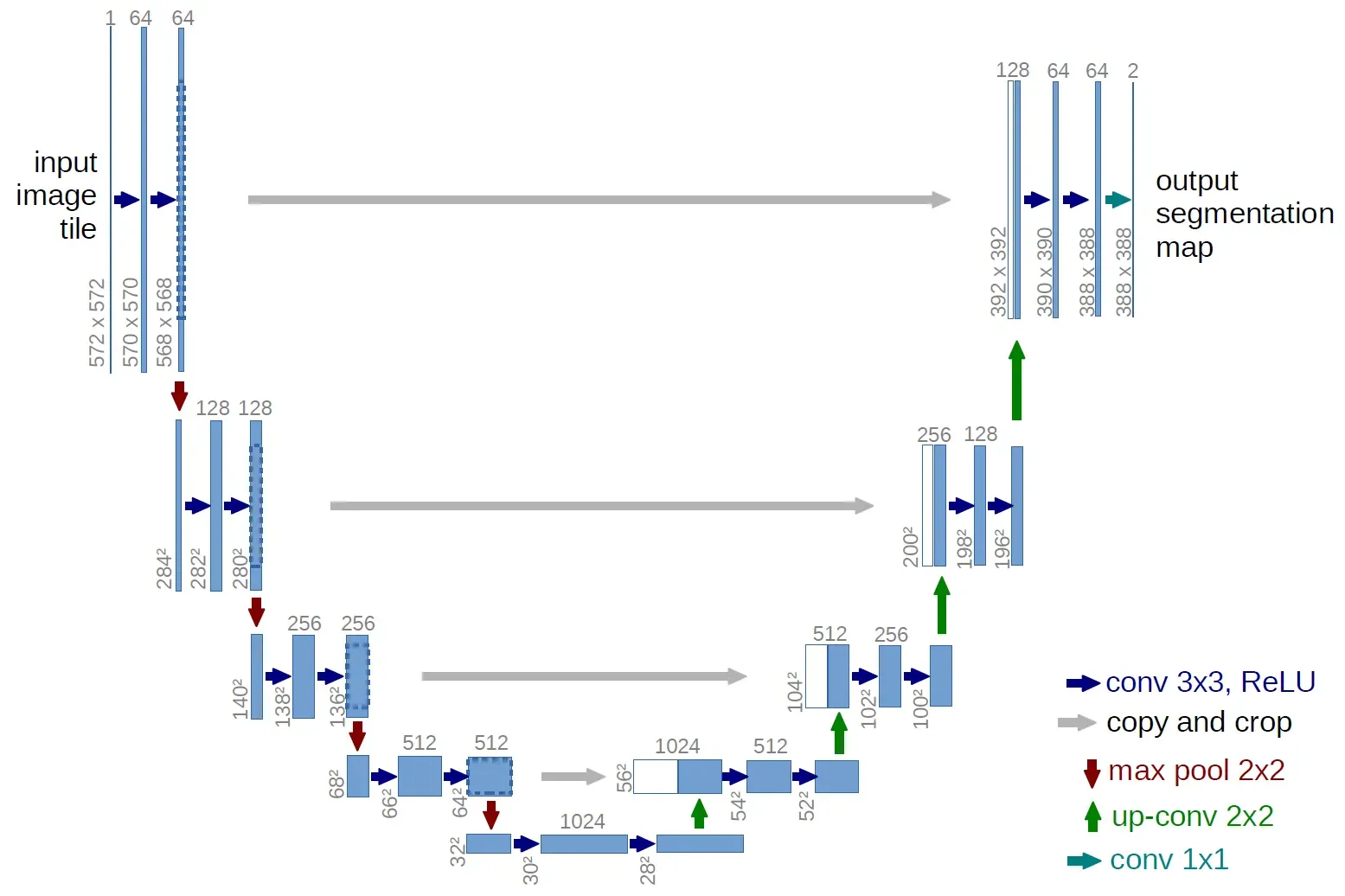
从 U-Net 的网络结构来看,最直接的感受是其 U 形的结构,这也是其命名的由来。对于 U-Net 来说,有如下的两个特点:
- U 形结构:U-Net 由编码器(上图左侧的收缩路径(Contracting Path))和解码器(上图右侧的扩张路径(Expansive Path))组成。
- 跳跃连接:在 U 形结构的左侧收缩路径和右侧扩张路径之间有跳跃连接(skip connections)将编码器的特征图与解码器的特征图相连接,这种结构有助于保留高分辨率信息。同时,跳跃连接有助于解决梯度消失问题,同时帮助网络学习到更好的特征表示,这些连接使网络能够利用不同层级的特征信息。
2.2. 损失函数
在训练过程中,U-Net 通常使用像素级别的损失函数,如交叉熵损失函数:
3. PyTorch 实践
3.1. 数据集
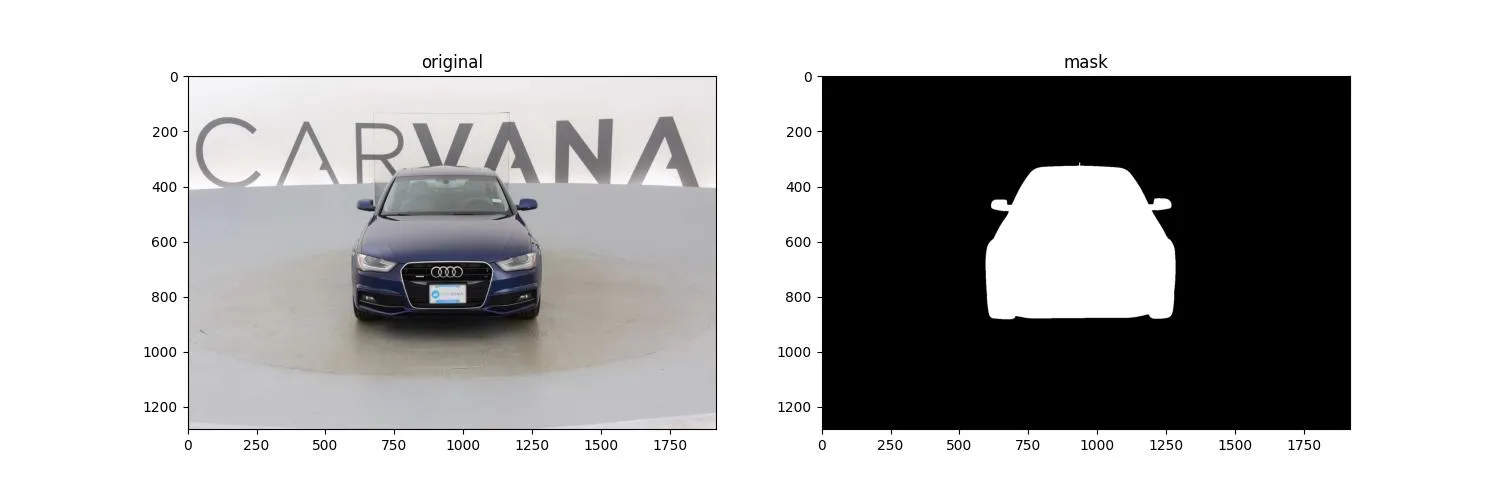
实验采用的数据集来自于 Kaggle 的 carvana-image-masking-challenge,数据集的链接见参考文献[3]。图片的示例如下图所示:
参照参考文献[4],构建数据集需要遵循数据加载的基本框架,最终形成如下的数据处理代码:
from torch.utils.data.dataset import Dataset
from torchvision import transforms
from PIL import Image
import os
class CarvanaDataset(Dataset):
def __init__(self, root_path):
self.root_path = root_path
self.images = sorted([root_path + "/train/" + i for i in os.listdir(root_path + "/train/")])
self.masks = sorted([root_path + "/train_masks/" + i for i in os.listdir(root_path + "/train_masks/")])
self.transform = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor()])
def __getitem__(self, index):
img = Image.open(self.images[index]).convert("RGB")
mask = Image.open(self.masks[index]).convert("L")
return self.transform(img), self.transform(mask), self.images[index]
def __len__(self):
return len(self.images)
注:数据链接[3]中解压出来的文件夹很多,这里只取 train 文件夹和 train_masks 文件夹。
3.2. 构建模型
当然,从现在再回过头来看 U-Net 的网络结构,里面的卷积+池化的过程相比于 Resnet 等已经显得简单了很多,而且原始的论文中使用的网络结构相比较而言也是浅,为遵从对原理的掌握,这里还是保持与原文的一致,首先是基本模块,包含卷积,激活:
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv(x)
通过对基本模块的封装,可以构造出 U 形网络中下采样的部分:
class DownSample(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = DoubleConv(in_channels, out_channels)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
down = self.conv(x)
p = self.pool(down)
return down, p
注:下采样部分的输出包括了两个部分,一个是继续向下传递的 down,另一个是向右传递的 p。
另一部分是 U 形网络中的上采样部分:
class UpSample(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = nn.ConvTranspose2d(in_channels, in_channels//2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
x = torch.cat([x1, x2], 1)
return self.conv(x)
将上述的下采样部分和上采样部分结合在一起便可以构造出 U-Net 的网络结构:
class UNetModel(nn.Module):
def __init__(self, in_channels=3, num_classes=1):
super().__init__()
self.down_conv_1 = DownSample(in_channels, 64)
self.down_conv_2 = DownSample(64, 128)
self.down_conv_3 = DownSample(128, 256)
self.down_conv_4 = DownSample(256, 512)
self.bottle_neck = DoubleConv(512, 1024)
self.up_conv_1 = UpSample(1024, 512)
self.up_conv_2 = UpSample(512, 256)
self.up_conv_3 = UpSample(256, 128)
self.up_conv_4 = UpSample(128, 64)
self.out = nn.Conv2d(in_channels=64, out_channels=num_classes, kernel_size=1)
def forward(self, x):
down_1, p1 = self.down_conv_1(x)
down_2, p2 = self.down_conv_2(p1)
down_3, p3 = self.down_conv_3(p2)
down_4, p4 = self.down_conv_4(p3)
b = self.bottle_neck(p4)
up_1 = self.up_conv_1(b, down_4)
up_2 = self.up_conv_2(up_1, down_3)
up_3 = self.up_conv_3(up_2, down_2)
up_4 = self.up_conv_4(up_3, down_1)
out = self.out(up_4)
return out
通过 torchinfo.summary() 函数,我们打印出 U-Net 的网络结构:
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
UNetModel [1, 1, 512, 512] --
├─DownSample: 1-1 [1, 64, 512, 512] --
│ └─DoubleConv: 2-1 [1, 64, 512, 512] --
│ │ └─Sequential: 3-1 [1, 64, 512, 512] 38,720
│ └─MaxPool2d: 2-2 [1, 64, 256, 256] --
├─DownSample: 1-2 [1, 128, 256, 256] --
│ └─DoubleConv: 2-3 [1, 128, 256, 256] --
│ │ └─Sequential: 3-2 [1, 128, 256, 256] 221,440
│ └─MaxPool2d: 2-4 [1, 128, 128, 128] --
├─DownSample: 1-3 [1, 256, 128, 128] --
│ └─DoubleConv: 2-5 [1, 256, 128, 128] --
│ │ └─Sequential: 3-3 [1, 256, 128, 128] 885,248
│ └─MaxPool2d: 2-6 [1, 256, 64, 64] --
├─DownSample: 1-4 [1, 512, 64, 64] --
│ └─DoubleConv: 2-7 [1, 512, 64, 64] --
│ │ └─Sequential: 3-4 [1, 512, 64, 64] 3,539,968
│ └─MaxPool2d: 2-8 [1, 512, 32, 32] --
├─DoubleConv: 1-5 [1, 1024, 32, 32] --
│ └─Sequential: 2-9 [1, 1024, 32, 32] --
│ │ └─Conv2d: 3-5 [1, 1024, 32, 32] 4,719,616
│ │ └─ReLU: 3-6 [1, 1024, 32, 32] --
│ │ └─Conv2d: 3-7 [1, 1024, 32, 32] 9,438,208
│ │ └─ReLU: 3-8 [1, 1024, 32, 32] --
├─UpSample: 1-6 [1, 512, 64, 64] --
│ └─ConvTranspose2d: 2-10 [1, 512, 64, 64] 2,097,664
│ └─DoubleConv: 2-11 [1, 512, 64, 64] --
│ │ └─Sequential: 3-9 [1, 512, 64, 64] 7,078,912
├─UpSample: 1-7 [1, 256, 128, 128] --
│ └─ConvTranspose2d: 2-12 [1, 256, 128, 128] 524,544
│ └─DoubleConv: 2-13 [1, 256, 128, 128] --
│ │ └─Sequential: 3-10 [1, 256, 128, 128] 1,769,984
├─UpSample: 1-8 [1, 128, 256, 256] --
│ └─ConvTranspose2d: 2-14 [1, 128, 256, 256] 131,200
│ └─DoubleConv: 2-15 [1, 128, 256, 256] --
│ │ └─Sequential: 3-11 [1, 128, 256, 256] 442,624
├─UpSample: 1-9 [1, 64, 512, 512] --
│ └─ConvTranspose2d: 2-16 [1, 64, 512, 512] 32,832
│ └─DoubleConv: 2-17 [1, 64, 512, 512] --
│ │ └─Sequential: 3-12 [1, 64, 512, 512] 110,720
├─Conv2d: 1-10 [1, 1, 512, 512] 65
==========================================================================================
Total params: 31,031,745
Trainable params: 31,031,745
Non-trainable params: 0
Total mult-adds (G): 218.60
==========================================================================================
Input size (MB): 3.15
Forward/backward pass size (MB): 1277.17
Params size (MB): 124.13
Estimated Total Size (MB): 1404.44
==========================================================================================
3.3. 模型训练
详细代码如下:
from models.unet.carvana_data import CarvanaDataset
from torch.utils.data import DataLoader, random_split
from torch import optim, nn
from tqdm import tqdm
import torch
from models.unet.unet_model import UNetModel
from models.unet.plot_util import plot_losses
class UNet:
def __init__(self, WORKING_DIR=None):
self.WORKING_DIR = WORKING_DIR
def train(self):
# 1. 加载数据
train_dataset = CarvanaDataset(self.WORKING_DIR)
generator = torch.Generator().manual_seed(25)
train_dataset, val_dataset = random_split(train_dataset, [0.8, 0.2], generator=generator)
device = "cuda" if torch.cuda.is_available() else "cpu"
if device == "cuda":
num_workers = torch.cuda.device_count() * 4
LEARNING_RATE = 3e-4
BATCH_SIZE = 16
train_dataloader = DataLoader(dataset=train_dataset,
num_workers=num_workers,
pin_memory=False,
batch_size=BATCH_SIZE,
shuffle=True)
val_dataloader = DataLoader(dataset=val_dataset,
num_workers=num_workers,
pin_memory=False,
batch_size=BATCH_SIZE,
shuffle=True)
model = UNetModel(in_channels=3, num_classes=1).to(device)
optimizer = optim.AdamW(model.parameters(), lr=LEARNING_RATE)
criterion = nn.BCEWithLogitsLoss()
EPOCHS = 200
train_losses = []
val_losses = []
best_val = float('inf')
for epoch in tqdm(range(EPOCHS), desc="EPOCHS", leave=True):
model.train()
train_running_loss = 0
for idx, img_mask in enumerate(tqdm(train_dataloader, desc="Training", leave=True)):
img = img_mask[0].float().to(device)
mask = img_mask[1].float().to(device)
y_pred = model(img)
optimizer.zero_grad()
loss = criterion(y_pred, mask)
train_running_loss += loss.item()
loss.backward()
optimizer.step()
train_loss = train_running_loss
train_losses.append(train_loss)
# 在验证集上验证
model.eval()
val_running_loss = 0
with torch.no_grad():
for idx, img_mask in enumerate(tqdm(val_dataloader, desc="Validation", leave=True)):
img = img_mask[0].float().to(device)
mask = img_mask[1].float().to(device)
y_pred = model(img)
loss = criterion(y_pred, mask)
val_running_loss += loss.item()
val_loss = val_running_loss
if val_loss < best_val:
best_val = val_loss
torch.save(model.state_dict(), 'best_unet.pth')
val_losses.append(val_loss)
# INFO: 记录
EPOCHS_plot = []
train_losses_plot = []
val_losses_plot = []
for i in range(0, EPOCHS, 5):
EPOCHS_plot.append(i)
train_losses_plot.append(train_losses[i])
val_losses_plot.append(val_losses[i])
print(f"EPOCHS_plot: {EPOCHS_plot}")
print(f"train_losses_plot: {train_losses_plot}")
print(f"val_losses_plot: {val_losses_plot}")
plot_losses(EPOCHS_plot, train_losses_plot, val_losses_plot, "train_val_losses.jpg")
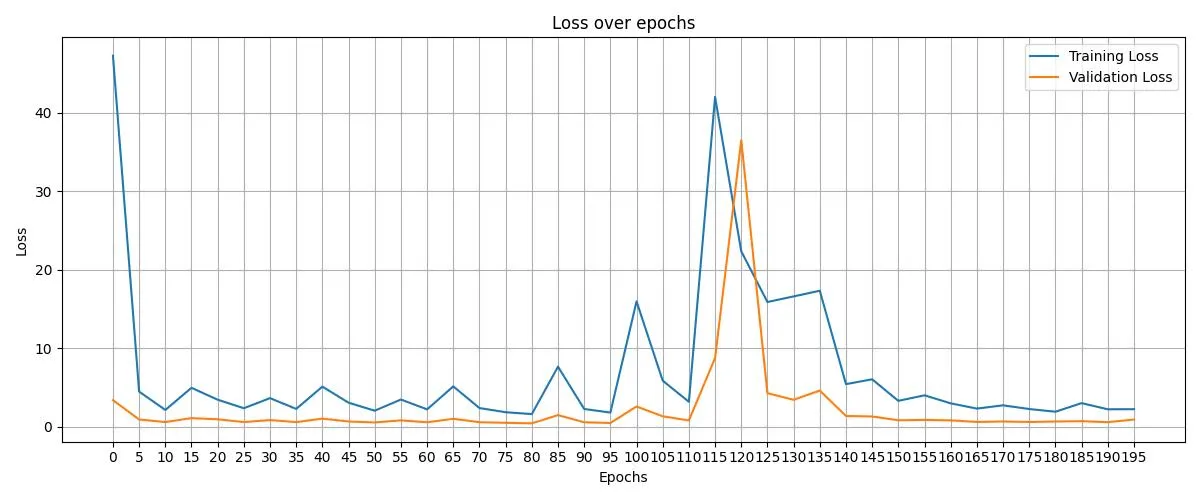
在训练的过程中,我们也记录了损失函数的变化:
在上述的构建模型的代码中,并未增加利于模型训练的一些技巧和方法,如 Batch Normalization 或者 Dropout 等方法,例如我们可以在模型的构建过程中增加 Batch Normalization,具体代码如下:
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels), # 增加 Batch Normalization
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels), # 增加 Batch Normalization
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv(x)
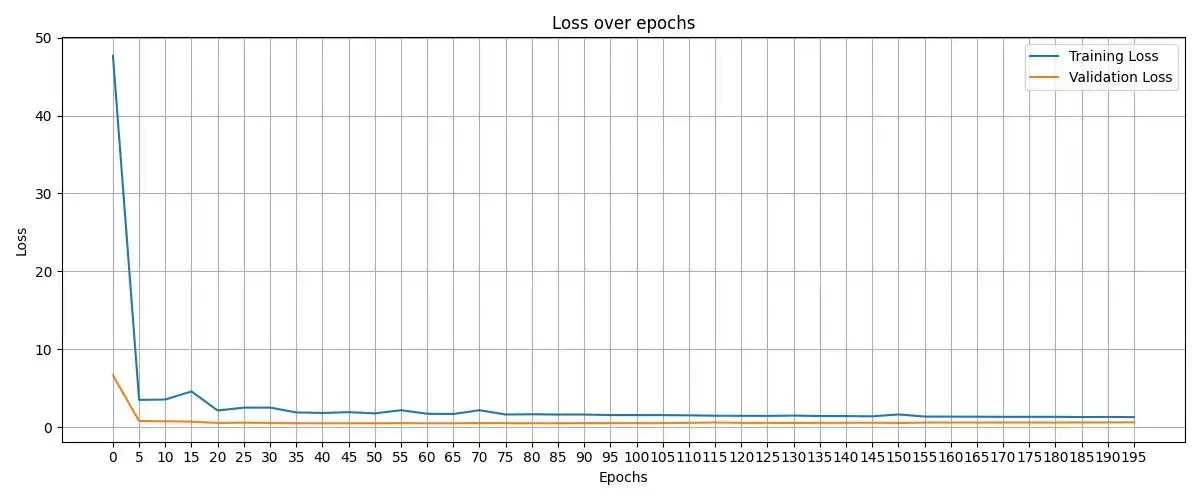
增加完,训练时收敛的会更加平稳:
3.4. 模型预测
训练完成后,我们保存了在验证集上效果最好的模型 best_unet.pth,接下来需要通过模型直接对新的图片预测,直接上代码,以下是预测部分的代码:
def predict(self, img, model_path):
w, h = img.size
ori_size = (h, w)
transform = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor()])
device = "cuda" if torch.cuda.is_available() else "cpu"
model = UNetModel(in_channels=3, num_classes=1).to(device)
model.load_state_dict(torch.load(model_path,
map_location=torch.device(device),
weights_only=True))
# 开始推理
model.eval()
with torch.inference_mode():
tensor_image = transform(img)
tensor_image = tensor_image.float().to(device)
# 增加 batch 维度
pred_mask = model(tensor_image.unsqueeze(0))
# 取消 batch 维度
pred_mask = pred_mask.squeeze(0)
img_resize = transforms.Resize(ori_size)
pred_mask = img_resize(pred_mask).permute(1,2,0)
pred_mask = pred_mask.cpu().detach()
pred_mask[pred_mask < 0] = 0
pred_mask[pred_mask > 0] = 1
numpy_image = pred_mask.numpy()
numpy_image = (numpy_image * 255).astype(np.uint8)
numpy_image = numpy_image.squeeze(-1)
return Image.fromarray(numpy_image)
注:在最终将 tensor 格式转换成 PIL 格式时,用到了
numpy_image.squeeze(-1),这是因为最终的预测图是个灰度图,在 PIL 的fromarray()对单通道数组的维度要求是(H, W)而非(H, W, 1),当通道维度被保留为 1 时,PIL 无法识别该数组为合法的灰度图格式,因此要将最后一维去掉。
可以对部分结构做个可视化,如下图:
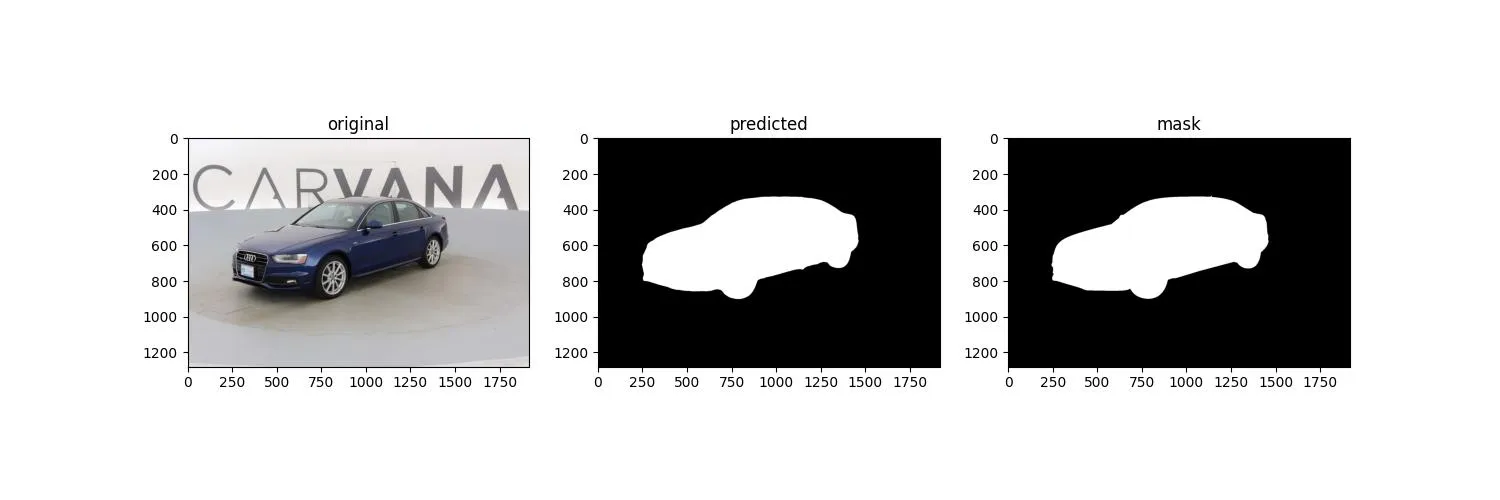
4. 总结
放眼现在的分割场景,U-Net 网络在实际的生产场景中仍具有不可替代的作用,如在智慧工厂中的分割问题。但是上述描述的基本的网络结构在应对复杂的问题时,仍具有泛化能力差,训练时间长等一系列的问题,可以基于后续的更先进的一些算法提升模型整体的能力,在这里,我们需要从 U-Net 网络中学习到的是如何应用 CNN 网络处理分割的问题,以及跳跃连接在其中所起到的作用。
参考文献
[1] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]//Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer International Publishing, 2015: 234-241.
[2] Kirillov A, He K, Girshick R, et al. Panoptic segmentation[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 9404-9413.
[3] https://www.kaggle.com/c/carvana-image-masking-challenge/data
[4] https://docs.pytorch.org/tutorials/beginner/basics/data_tutorial.html